Utiliser AWS pour déployer un projet de startup : Partie 2 - Backend
Dans le dernier chapitre…
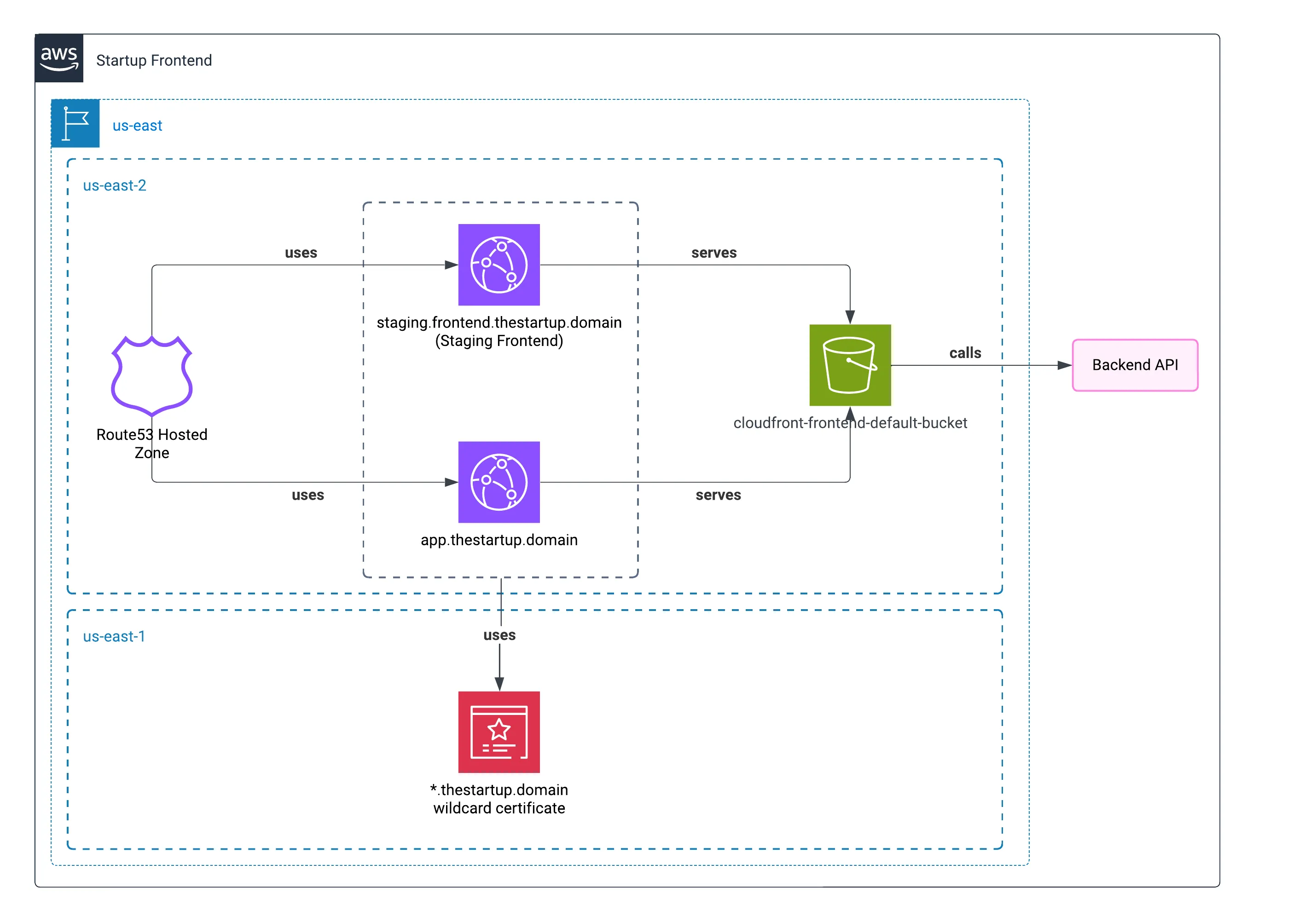
Dans le dernier article, j’ai montré comment le frontend de la startup a été déployé. En tirant parti du service de ressources statiques et de l’utilisation d’un CDN, cela a bien sûr contribué à offrir une expérience frontend disponible.
Maintenant, je vais expliquer les différentes ressources du backend, où résidait la majeure partie de la complexité.
Voici le diagramme complet du backend.

Infrastructure as Code (IaC)
Nous avons utilisé Terraform pour construire et déployer les différents services à travers l’infrastructure AWS.
On a encapsulé le code dans différents modules, puisqu’ils pouvaient être réutilisés dans la définition de l’architecture et parce qu’on avait besoin de réduire les changements entre les différents environnements.
Configuration du sous-réseau public
Buckets S3
On avait deux buckets S3 : un pour stocker les avatars des utilisateurs et l’autre pour stocker les logs du Load Balancer.
Comme dans le chapitre précédent, on servait les avatars via CloudFront - la méthode la plus rapide pour nos utilisateurs. On a configuré le CDN spécifiquement pour le marché nord-américain où se trouvait notre base principale d’utilisateurs.

NAT Gateway
Le NAT Gateway a joué un rôle crucial dans notre architecture en permettant aux conteneurs du sous-réseau privé d’accéder à Internet de manière sécurisée. Comme nos conteneurs ECS Fargate devaient télécharger des paquets NPM et des dépendances Docker pendant le déploiement, la passerelle NAT fournissait cette connectivité sortante tout en gardant les conteneurs inaccessibles depuis l’Internet public.
Tu sais probablement qu’on n’avait pas besoin d’une connexion entrante directe vers nos conteneurs. La passerelle NAT était placée dans le sous-réseau public et gérait la traduction des adresses IP privées vers publiques, agissant comme un pont sécurisé entre nos ressources privées et Internet.

Load Balancers d’Applicatifs (ALB)
Pour rediriger le trafic des utilisateurs vers nos conteneurs, on a dû utiliser des Load Balancers applicatifs - un service AWS basé sur la couche 7 applicative. On peut définir un ensemble de règles à leur création, donc peu importe le port sur lequel on sert notre application dans les conteneurs ; l’ALB gère toute la redirection du trafic et maintient aussi les utilisateurs sur des conteneurs spécifiques si on active cette option.

Load Balancers de Réseau (NLB)
On a dû exposer notre instance locale de PHPMyAdmin et Metabase au réseau privé, mais comme ils vivaient dans le même groupe de conteneurs que notre outil d’administration, on ne voulait pas utiliser un load balancer applicatif. À la place, on avait besoin d’une façon alternative de partager nos applications sur différents ports par rapport à ceux utilisés typiquement pour les applications web, et utiliser le Load Balancer réseau était la seule solution.

Accès VPN
Pour permettre à nos employés d’accéder à notre portail d’administration, on a dû configurer une petite instance EC2 avec OpenVPN. Ensuite, on a créé manuellement l’accès pour chaque employé. Comme on était une startup, on ne s’inquiétait pas trop d’avoir du SAML ou d’autres types d’authentification, et le VPN marchait super bien pour nos employés en Amérique du Nord et du Sud.

ACM (Certificate Manager)
Pour finir, le Certificate Manager s’occupait de créer le certificat pour servir notre site en HTTPS. Pas grand-chose d’autre à dire, c’est juste indispensable de nos jours.
Configuration du Sous-réseau Privé
Cluster ECS Fargate
Nous avons configuré deux clusters ECS différents : un pour chaque environnement. Bien sûr, pour les conteneurs qui vivaient en staging, nous leur avons donné moins de mémoire et d’utilisation CPU par rapport à ceux de production.
Lorsque nous avons créé la v1 du produit, nous utilisions ECS combiné avec EC2. Puis Fargate est sorti avec la promesse de ne plus gérer de serveurs (Serverless), et nous avons progressivement migré au cours des deux années suivantes.
Services d’Administration
Une plateforme web ordinaire pour vérifier toutes les informations liées aux utilisateurs, leurs interactions et mettre à jour toutes les données publiques sans nécessiter qu’ils le fassent depuis la plateforme. Elle était hébergée sur ECS Fargate et servie uniquement via le VPN. Cela était servi avec l’Application Load Balancer.

Services Privés
Les services privés comprenaient quelques conteneurs pour servir certaines analyses utilisant Metabase et un outil PHPMyAdmin pour les requêtes MySQL.
Monitoring
Nous avons toujours utilisé CloudWatch combiné avec des graphiques RDS pour mesurer l’utilisation de la base de données. CloudWatch était suffisant pendant la durée du projet et était assez économique. Ce qui me manquait par rapport à d’autres outils de logging était la capacité d’afficher des couleurs selon le type de logs.
Dans les années suivantes, nous avons utilisé DataDog. En comparaison, Datadog fournit plus d’outils pour vraiment résumer et visualiser vos logs et la stabilité de l’application, au prix d’un coût financier plus élevé.
RDS
Dans la première étape du lancement, nous avons utilisé AWS RDS pour MySQL ; cependant, au fil des ans, et depuis qu’Amazon a lancé différentes améliorations de ses services, nous avons fait une migration complète vers AWS Aurora Serverless pour les deux environnements. Nous n’avons jamais eu de grands pics provenant des lectures de base de données, donc une base de données serverless avait du sens à ce moment-là.
La base de données serverless était plus que suffisante pour supporter les différentes opérations CRUD à travers l’application. Comme l’application était principalement utilisée du lundi au vendredi, nous avions une utilisation prévisible, mais le temps de réponse n’était pas une priorité.
Déploiement
Le processus de déploiement était relativement complexe — non pas en raison de multiples pipelines, mais parce qu’il fallait construire des images Docker avec une configuration spécifique à la production, puis configurer AWS pour le déploiement lors des mises à jour d’images.
La première étape consistait à prendre le projet, construire une image ECR, et la transmettre à AWS.
name: Déploiement vers Staging
on: push: branches: [main]
jobs: push_to_ecr: name: Construction et envoi vers ECR runs-on: ubuntu-latest steps: - name: Checkout uses: actions/checkout@v4 - name: Configuration des identifiants AWS uses: aws-actions/configure-aws-credentials@v4 with: aws-access-key-id: ${{ secrets.AWS_ECR_GITHUB_ID }} aws-secret-access-key: ${{ secrets.AWS_ECR_GITHUB_KEY }} aws-region: us-east-2 - name: Connexion à Amazon ECR id: login-ecr uses: aws-actions/amazon-ecr-login@v2 - name: Construction, étiquetage et envoi de l'image vers Amazon ECR id: thestartup-admin env: ECR_REGISTRY: ${{ steps.login-ecr.outputs.registry }} ECR_REPOSITORY: thestartup-container-admin IMAGE_TAG: staging run: | printf '{"version":"%s"}' ${{ github.sha }} > src/version.json docker build -t $ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG -t $ECR_REGISTRY/$ECR_REPOSITORY:latest --target staging . docker push $ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG docker push $ECR_REGISTRY/$ECR_REPOSITORY:latest echo "::set-output name=image::$ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG" Si vous examinez le contenu du fichier src/version.json, nous l’utilisions pour vérifier que la version actuelle du conteneur était bien déployée dans ECS. Ce chemin nous permettait de confirmer que le conteneur fonctionnait correctement.
De plus, nous devions déclencher des événements une fois que nous faisions des changements dans AWS, et pour cela nous avons tiré parti de CloudWatch Events.
Après cela, nous utilisions AWS CodePipeline, un service utilisé pour lancer différents workflows pour déployer votre code dans les services AWS.
AWS CodePipeline gérait plusieurs tâches : celles liées à la détection des changements de code, la construction de l’image (en utilisant CodeBuild) puis en utilisant CodeDeploy pour envoyer le code à tous les conteneurs.

Ce que je ferais aujourd’hui
Limiter l’accès AWS
Tous les développeurs partageaient beaucoup d’accès en lecture et écriture à ce moment-là, car c’était plus facile d’écrire et de fournir ce type d’accès dans AWS IAM. Aujourd’hui, je limiterais l’accès de chaque développeur uniquement aux ressources dont ils ont réellement besoin, en utilisant des rôles si possible.
Feature Flags
Lorsque nous lancions différentes fonctionnalités, nous changions l’API et le frontend assez fréquemment. Comme nous utilisions Ionic pour créer la version mobile de l’application, nous avions parfois des problèmes avec des utilisateurs qui utilisaient une ancienne version de l’application et commençaient à voir des défaillances. La solution pour cela sera toujours d’utiliser des feature flags. Avec cela, nous pouvons nous assurer que seuls les utilisateurs de la dernière version de nos applications obtiendront les dernières fonctionnalités. Ou si nous voulons commencer un déploiement progressif, nous pourrions utiliser seulement 10% de notre base d’utilisateurs pour tester une nouvelle fonctionnalité que nous préparions.

Triage
Au début, nous n’avions pas de système approprié pour gérer et catégoriser les incidents ou les erreurs. Quand quelque chose tournait mal en production, nous sautions tous pour le réparer sans documentation appropriée ou évaluation des priorités. Aujourd’hui, j’implémenterais un système de triage approprié où les incidents sont catégorisés selon leur gravité (P0, P1, P2, etc.), leur impact sur les utilisateurs et leurs implications commerciales.
Ce système de triage nous aiderait à :
- Mieux allouer les ressources des développeurs en fonction de la priorité de l’incident. Nous pouvons compter les 5 principales erreurs, par exemple, et établir quel développeur de l’équipe devrait être responsable de les corriger.
- Maintenir une documentation appropriée des problèmes de production et créer des Rapports d’Incidents appropriés si possible.
- Créer des modèles pour prévenir des incidents similaires à l’avenir.
- Établir des canaux de communication clairs et des voies d’escalade lorsque des problèmes surviennent. Normalement, nous utilisions Slack, directement déclenché depuis chaque conteneur, mais si nous utilisons un outil de Triage, celui-ci pourrait être responsable de rediriger les erreurs.
Avoir une approche structurée de la gestion des incidents nous aurait fait gagner du temps et réduit le stress de la gestion des problèmes de production, particulièrement en considérant notre architecture conteneurisée à travers de multiples environnements.

Pour les services privés, peut-être utiliser une instance EC2
Bien que le serverless et les conteneurs soient la norme dans le développement d’applications moderne, je pense aussi que parfois il est moins cher de maintenir un petit VPS en fonctionnement. Par exemple, quand nous utilisions EC2 pour servir le VPN par rapport aux services VPN coûteux que vous pouvez connecter à votre Réseau Amazon. Bien sûr, nous parlons de petites entreprises.