Usando AWS para desplegar un proyecto de Startup: Parte 2 - Backend
En el último capítulo…
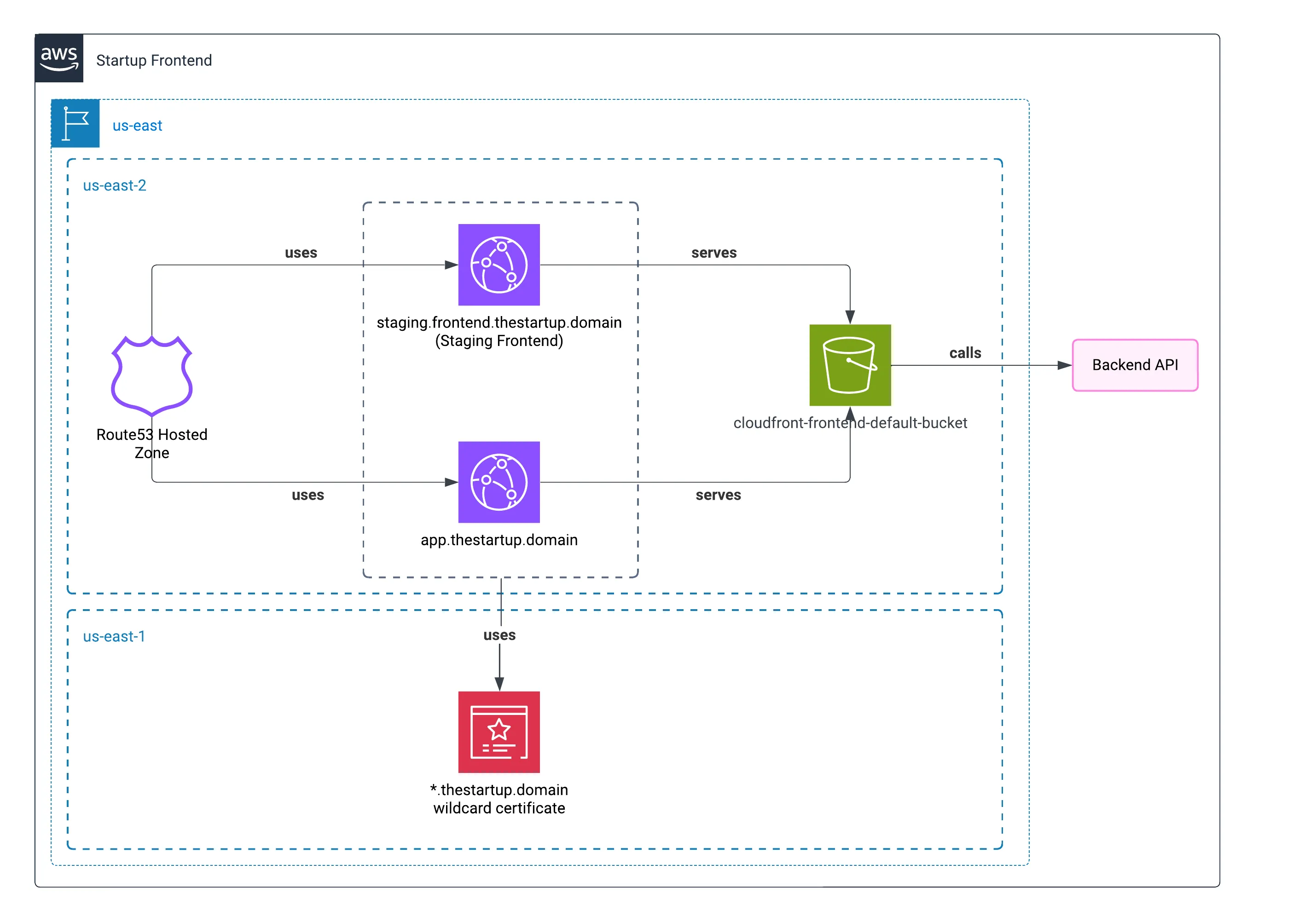
En la última publicación, mostré cómo se implementó el frontend de la startup. Aprovechando el servicio de recursos estáticos y utilizando una CDN, por supuesto, ayudó tener una experiencia frontend.
Ahora explicaré los diferentes recursos del backend, donde residía la mayor parte de la complejidad.
Aquí está el diagrama completo del backend.

Infraestructura como Código (IaC)
Utilizamos Terraform para construir e implementar los diferentes servicios en dos diferentes entornos de producción, con variables almacenadas en el servicio en la nube de Terraform.
Encapsulamos el código en diferentes módulos, ya que podían ser reutilizados en la definición de la arquitectura y porque necesitábamos reducir los cambios entre los diferentes entornos.
Configuración de subred pública
Buckets S3
Teníamos dos buckets S3: uno para almacenar avatares de usuarios y otro para almacenar registros del Balanceador de Carga de Aplicaciones.
Similar a nuestro enfoque en el capítulo anterior, servimos avatares de usuarios a través de CloudFront—el método de entrega más rápido para nuestros usuarios. Configuramos la CDN específicamente para el mercado norteamericano donde nuestra aplicación tenía su base principal de usuarios.

Puerta de enlace NAT
La puerta de enlace NAT jugó un papel crucial en nuestra arquitectura al permitir que los contenedores en la subred privada accedieran a internet de forma segura. Dado que nuestros contenedores ECS Fargate necesitaban descargar paquetes NPM y dependencias de Docker durante la implementación, la puerta de enlace NAT proporcionó esta conectividad saliente a internet mientras mantenía los contenedores inaccesibles desde internet público.
Como probablemente sabes, no necesitábamos una conexión directa entrante a nuestros contenedores. La puerta de enlace NAT se colocó en la subred pública y manejó la traducción de direcciones IP privadas a públicas, actuando efectivamente como un puente seguro entre nuestros recursos privados e internet.

Balanceadores de Carga de Aplicaciones (ALB)
Para redirigir el tráfico de los usuarios a nuestros contenedores, tuvimos que usar Balanceadores de Carga de Aplicaciones — un servicio de AWS que se basa en la Capa 7 de aplicaciones. Podemos establecer un grupo de reglas una vez que los creamos, por lo que no importa en qué puerto estemos sirviendo nuestra aplicación dentro de los contenedores; ALB manejará toda la redirección del tráfico, y también mantendrá a los usuarios en contenedores específicos si habilitamos esa opción.

Balanceadores de Carga de Red (NLB)
Tuvimos que exponer nuestra instancia local de PHPMyAdmin y Metabase a la red privada, pero como vivían dentro del mismo grupo de contenedores que nuestra herramienta de administración, no queríamos usar un balanceador de carga de aplicaciones. En su lugar, necesitábamos una forma alternativa de compartir nuestras aplicaciones en diferentes puertos en comparación con los que se usan típicamente para aplicaciones web, y usar el Balanceador de Carga de Red fue la única solución.

Acceso VPN
Para permitir que los trabajadores internos accedieran a nuestro portal de administración, tuvimos que preparar una pequeña instancia EC2 con OpenVPN. Luego, creamos manualmente el acceso para cada trabajador. Como era una startup, no importaba si teníamos SAML u otro tipo de autenticación, y la VPN funcionó bien para servir a trabajadores en América del Norte y del Sur.

ACM (Certificate Manager)
Finalmente, el Certificate Manager se encargó de crear el certificado para servir nuestro sitio a través de HTTPS. Nada más que decir, ya que es imprescindible hoy en día.
Configuración de subred privada

Cluster ECS Fargate
Configuramos dos clusters ECS diferentes: uno para cada entorno. Por supuesto, para los contenedores que viven en staging, les dimos menor memoria y uso de CPU en comparación con los de producción.
Cuando creamos la v1 del producto, usamos ECS combinado con EC2. Luego salió Fargate con la promesa de no administrar más servidores (Serverless), y nos mudamos gradualmente durante los siguientes dos años.
Servicios de administración
Una plataforma web común y corriente para verificar toda la información relacionada con los usuarios, sus interacciones y actualizar cualquier dato público sin requerir que lo hagan desde la plataforma. Se alojaba en ECS Fargate y se servía solo a través de la VPN. Esto se servía con el Balanceador de Carga de Aplicaciones.
Servicios privados
Los servicios privados incluían un par de contenedores para servir algunos análisis usando Metabase y una herramienta PHPMyAdmin para consultas MySQL.
Monitoreo
Siempre usamos CloudWatch combinado con gráficos RDS para medir qué tan pesado era el uso de la base de datos. CloudWatch fue suficiente durante el tiempo que el proyecto estuvo en funcionamiento, y era bastante económico. Lo que extrañé en comparación con otras herramientas de registro fue la capacidad de mostrar colores según el tipo de logs.
En años posteriores, usamos DataDog. En comparación, Datadog proporciona más herramientas para realmente resumir y visualizar tus logs y la estabilidad de la aplicación, a costa de ser más costoso financieramente.
RDS
En la primera etapa del lanzamiento, usamos AWS RDS para MySQL; sin embargo, con los años, y desde que Amazon lanzó diferentes mejoras a sus servicios, hicimos una migración completa a AWS Aurora Serverless para ambos entornos. Nunca tuvimos grandes picos provenientes de lecturas de base de datos, por lo que una base de datos serverless tenía sentido en ese momento.
La base de datos serverless fue más que suficiente para soportar las diferentes operaciones CRUD a través de la aplicación. Como la aplicación se usaba principalmente de lunes a viernes, teníamos un uso predecible, pero el tiempo de respuesta no era una prioridad.
Despliegue

El proceso de despliegue no era excesivamente complejo, pero requería varios pasos: construir las imágenes Docker con una configuración específica para producción y configurar AWS para realizar el despliegue automático cuando se generaba una nueva imagen Docker.
Para el primer paso, teníamos que tomar el proyecto, construir una imagen ECR y luego enviarla a AWS.
name: Despliegue a Staging
on: push: branches: [main]
jobs: push_to_ecr: name: Construyendo y enviando a ECR runs-on: ubuntu-latest steps: - name: Checkout uses: actions/checkout@v4 - name: Configurar credenciales AWS uses: aws-actions/configure-aws-credentials@v4 with: aws-access-key-id: ${{ secrets.AWS_ECR_GITHUB_ID }} aws-secret-access-key: ${{ secrets.AWS_ECR_GITHUB_KEY }} aws-region: us-east-2 - name: Iniciar sesión en Amazon ECR id: login-ecr uses: aws-actions/amazon-ecr-login@v2 - name: Construir, etiquetar y subir imagen a Amazon ECR id: thestartup-admin env: ECR_REGISTRY: ${{ steps.login-ecr.outputs.registry }} ECR_REPOSITORY: thestartup-container-admin IMAGE_TAG: staging run: | printf '{"version":"%s"}' ${{ github.sha }} > src/version.json docker build -t $ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG -t $ECR_REGISTRY/$ECR_REPOSITORY:latest --target staging . docker push $ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG docker push $ECR_REGISTRY/$ECR_REPOSITORY:latest echo "::set-output name=image::$ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG" Si observas el archivo src/version.json, lo utilizamos para verificar que el commit actual del contenedor estaba correctamente implementado en ECS. La ruta nos permitía confirmar que el contenedor se encontraba en ejecución.
Además, necesitábamos activar eventos una vez que hiciéramos cambios en AWS, y para eso aprovechamos CloudWatch Events.
Después de eso, usamos AWS CodePipeline, un servicio utilizado para iniciar diferentes flujos de trabajo para implementar tu código en servicios AWS.
AWS CodePipeline manejaba varias tareas: las relacionadas con la detección de cambios de código, la construcción de la imagen (usando CodeBuild) y luego usando CodeDeploy para enviar el código a todos los contenedores.
Cosas que haría hoy en día
Limitar acceso AWS
Todos los desarrolladores compartían muchos accesos de lectura y escritura en ese momento, ya que era más fácil escribir y proporcionar ese tipo de accesos en AWS IAM. Hoy, limitaría el acceso de cada desarrollador solo a los recursos que realmente necesitan, usando roles si es posible.
Feature Flags
Cuando lanzamos diferentes características, cambiamos la API y el frontend con bastante frecuencia. Como estábamos usando Ionic para crear la versión móvil de la aplicación, a veces teníamos problemas con usuarios que estaban usando una versión antigua de la aplicación y comenzaban a ver fallas. La solución para eso siempre será usar feature flags. Con eso, podemos asegurar que solo los usuarios de la última versión de nuestras aplicaciones obtendrán las últimas características. O si queremos comenzar un lanzamiento progresivo, podríamos usar solo el 10% de nuestra base de usuarios para probar una nueva característica que estábamos preparando.

Triage
Al principio, no teníamos un sistema adecuado para manejar y categorizar incidentes o errores. Cuando algo salía mal en producción, todos saltábamos a arreglarlo sin documentación adecuada o evaluación de prioridades. Hoy, implementaría un sistema de triage adecuado donde los incidentes se categorizan según su severidad (P0, P1, P2, etc.), impacto en los usuarios e implicaciones comerciales.
Este sistema de triage nos ayudaría a:
- Asignar mejor los recursos de desarrolladores según la prioridad del incidente. Podemos contar los 5 errores principales, por ejemplo, y establecer qué desarrollador del equipo debería ser responsable de arreglarlos.
- Mantener documentación adecuada de problemas de producción y crear Informes de Incidentes adecuados si es posible.
- Crear patrones para prevenir incidentes similares en el futuro.
- Establecer canales de comunicación claros y rutas de escalamiento cuando surjan problemas. Normalmente usábamos Slack, directamente activado desde cada contenedor, pero si usamos una herramienta de Triage, esa podría ser responsable de redirigir los errores.
Tener un enfoque estructurado para la gestión de incidentes nos habría ahorrado tiempo y reducido el estrés de manejar problemas de producción, especialmente considerando nuestra arquitectura containerizada a través de múltiples entornos.

Para servicios privados, tal vez usar una instancia EC2
Ya que serverless y contenedores son la norma en el desarrollo de aplicaciones moderno, también pienso que a veces es más barato mantener funcionando un VPS pequeño. Por ejemplo, cuando usábamos EC2 para servir la VPN en comparación con servicios VPN costosos que puedes conectar a tu Red Amazon. Por supuesto, estamos hablando de pequeñas empresas.